Using Machine Learning and SageMaker with Tensorflow to Recognize Tulip Varieties
Here at SpinDance, IoT Consultant and Software development company, we’ve taken a keen interest in machine learning as a way to bring IoT software solutions to the next level for our clients. Since machine learning is a rapidly changing and improving area of technology, part of our job as software experts is to keep up with the newest changes as well as continuing to master existing tools and offerings to support our customers and their projects.
As a way to continue to sharpen our skills, we took on an in-house project, the Tulip App, an Android app that used machine vision to identify different varieties of tulips using the camera on a user’s mobile device. We chose this topic because being based out of Holland, Michigan means that every May we get to enjoy Tulip Time, a festival with roots stemming from the Netherlands where the entire town is adorned with tulips. There are thousands of tulips in dozens of varieties to see in Holland during this time of year, so we thought it would be relevant to make an app that can tell the name of each variety. We accomplished this by using Tensorflow deployed with SageMaker for training the model. After that, we deployed the model using an Android application and the Tensorflow Lite Android SDK.
Designing and Training a Machine Learning Model
In a lot of ways, machine learning projects can look like two separate projects: developing and training the machine learning model, and then deploying it for real-world application. A large portion of the time spent will be researching and experimenting with different approaches to model design and training. The other component of the project is setting up a way to access the prepared model, in the case of the tulip project, an Android app, that allows users to get data to the now-trained model for inferences. Models are only useful if one can actually use it.
So how did we go about training the model for our tulip identifier? In general, machine learning projects follow a similar pattern. The main phases of these projects tend to be Design, Data Preparation, Model Fitting, and Interface Development and Deployment. Here’s a diagram with more details on this process:
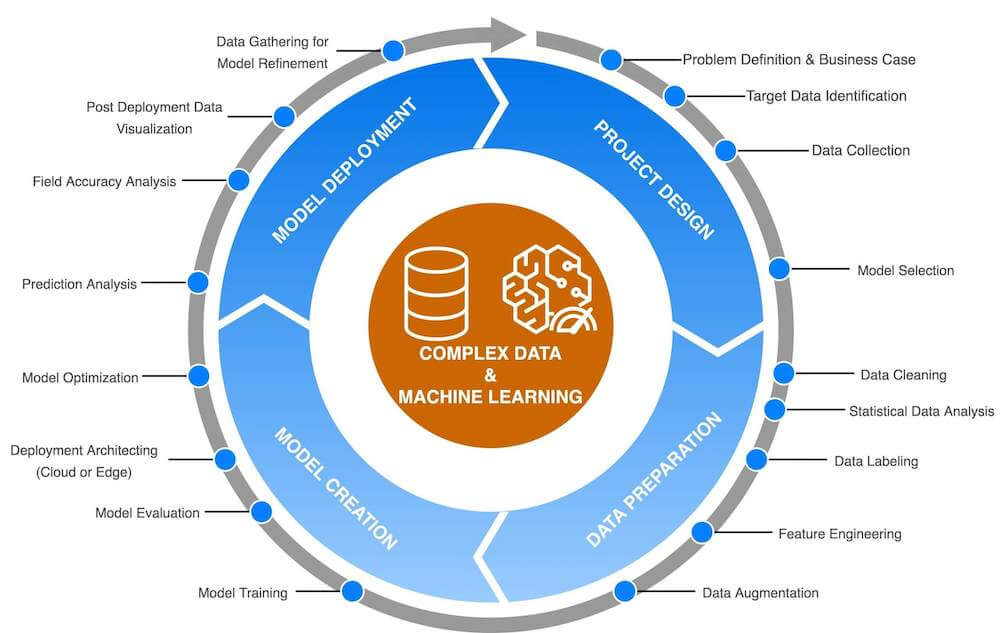
There are many toolkits and platforms that facilitate this workflow. At SpinDance, we prefer to use Amazon Web Services because the IoT offerings tend to be more mature and new features tend to be available ahead of the curve. Some of the key functionality AWS has that we took advantage of was:
- AWS SageMaker
- EC2 Spot Instances for running training
- Tensorflow integrations, including Tensorboard
- S3, for storing training and test data
Using these offerings and a few others, AWS allows us to train and deploy machine learning models with relative ease when compared with unmanaged solutions. Here’s a high-level overview of the way we fit all these components together:
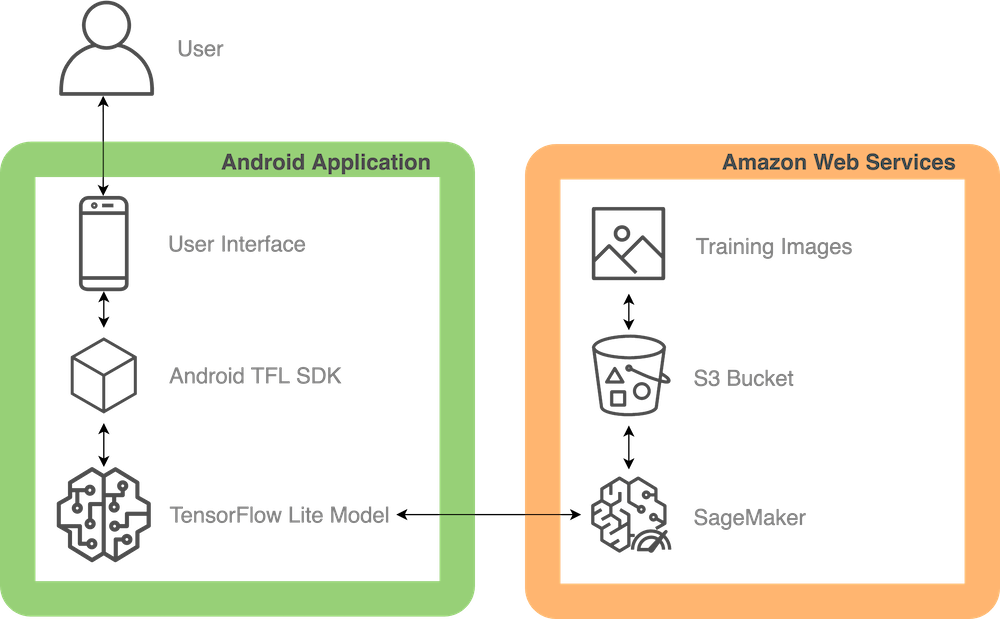
What is SageMaker?
Amazon SageMaker, much like many offerings from AWS, is a family of machine learning solutions that allow for fully managed machine learning model training and deployment as well as a broad range of tertiary functionality like data labeling, inference monitoring, and performance profiling. SageMaker is extremely useful for machine learning development because it allows an engineer or data scientist to set up and tear down training resources without having to manually configure and manage EC2 instances and all the other infrastructure that is required for a robust machine learning pipeline.
Using SageMaker, we built a pipeline that allowed us to ingest a large volume of labeled pictures of flowers in order to train our model to recognize tulips. Storing the photos in an S3 bucket, when the pipeline was kicked off we would move them into an EBS instance and use them to train our model hosted on an EC2 spot instance. The EBS and EC2 instances were fully managed by SageMaker, which allowed us to focus on getting a working model instead of fiddling around with EC2 and docker configuration.
Selecting the Machine Learning Model
In this case, we are using a Tensorflow Lite model because it is an effective solution for mobile applications. We wanted to keep the persistent cloud infrastructure, and therefore cost, to a minimum due to this being a training project so we didn’t want to run inference in the cloud. Tensorflow Lite is the perfect fit for a project where you don’t want to tax the device running the inference too heavily. Additionally, the model is much smaller which makes the app size significantly smaller as well, saving on storage. We then used this model on an Android app using the Tensorflow Lite Android SDK in order to infer information about the images captured in real-time on a video stream from the camera of the device. Here’s a picture of the final product:

As you might have noticed in the screenshot above, the confidence of our model was pretty low. A key consideration here is that there is a difference between confidence and accuracy. The above image shows the model saying “I think this is a Saigon tulip”, which it is! However, it’s only 21% confident in that inference.
How Complex Should the Machine Learning Model Be?
In the end, we discovered the limitations of a lightweight model combined with a lack of good training data. The model can certainly recognize flowers, and can even infer if a flower is a tulip. However, the difference between different varieties of tulips was too subtle for the model to pick up on consistently. One major limitation was having the model be directly on the device. A more complex model deployed on the cloud would likely be able to make much more accurate inferences. This is a common balancing act in machine learning projects. How complex should the model be? Too complex and the computational power and storage demands could be expensive, too simple and the model may not give good inferences about new data. In this case, we were limited by the power and storage available on common android devices, leading to a model that didn’t have enough horsepower to give us acceptable inferences. Despite the model’s final shortcoming, the knowledge we gained along the way about SageMaker and Machine Vision was invaluable in allowing us to keep up with the latest and greatest in machine learning platforms and techniques.
Are you looking to jumpstart a machine learning initiative at your company? Or perhaps you have a problem you think machine learning or computer vision might help solve? Let us help you! Feel free to drop us a line at hello@spindance.com. You may also find our IoT Bootcamps and free IoT webinars helpful.

About the Author
Peter Van Drunen is a Software Engineer at SpinDance. He is a full-stack web developer with experience in cloud and machine learning tools. When he’s not creating software he enjoys baking and long walks, when the Michigan weather allows.